Candidate : Create scoring data
Everything you need to know about creating Scoring Data to train a Custom Candidate Scoring Algorithm.
The quality of a scoring dataset plays a key role in the success of a scoring algorithm retraining.
The whole recruitment process can be seen from two different points of view:
- Recruiter viewpoint: finding the best profiles for a job offer
- Candidate viewpoint: finding interesting jobs for a candidate
In this guide we will focus on the candidate viewpoint, please refer to the recruiter viewpoint page for the recruiter viewpoint.
Table of Contents
- Use-case : Candidate Viewpoint - Scoring Jobs for a Candidate
- Submit data to HrFlow.ai team
- Quality of the Training Data
- Format of the Training Data
- Self-Submission
- No-Code : Simplifying Self-Submission Processes
1. Use-case : Candidate Viewpoint - Scoring Jobs for a Candidate
The candidate viewpoint illustrates a scenario where the candidate's destiny hinges on their own decisions and actions throughout the job-seeking process. Here, the primary objective is to find the best job opportunity that aligns with the candidate's career aspirations. This perspective prioritizes the candidate's needs and goals, aiming to secure a fulfilling and suitable employment opportunity.
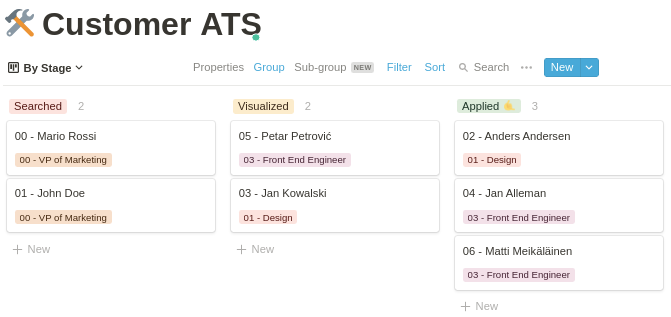
For this use case, we are going to consider the following example where an application status can take 3 values :
- Searched : the candidate searched for the job offer.
- Visualized: The candidate visualized and considered the details of the job offer.
- Applied: The candidate formally applied to the job offer.
Basic scoring algorithms such as "Blue & White Collars", available in Hrflow.ai marketplace, come with 91% accuracy on generic datasets. Retraining theses algorithms on your custom dataset leads to the following benefits:
- Highly reduces the false-positive results returned by the scoring engine
- Increases the overall accuracy by several percent on your own data
2. Submit data to HrFlow.ai team
Large Scale TrainingsThis submission approach is deprecated for large-scale training. Please follow the Large Scale Training guide.
I. Quality of the Training Data
The success of an Hrflow.ai retraining strongly relies on the quality of the data. We can consider 3 types of it :
1. Candidate profiles
The initial building block of the project, the candidate profiles, stands as the most intricate component. At HrFlow.ai, we rely on parsed profiles to retrain our models. It's evident that any variance in parsing such a complex object could detrimentally impact the model's learning process. Therefore, we emphasize the critical importance of utilizing HrFlow.ai's parsing.
In addition to CVs, we highly recommend submitting profile metadata, if available, in a JSON file format. This metadata may include additional information not present in the resume itself, such as the candidate's category or desired salary.
The recommended approach involves submitting raw CVs, which will subsequently undergo parsing by HrFlow.ai. Additionally, we recommend providing metadata files for each candidate.
Profiles naming conventionEach raw CV and candidate metadata should be named with the corresponding reference or id.
2. Job offers
A basic job offer typically includes just a job title and job description. However, we advise structuring the job details as comprehensively as possible. Including the job location, whether it's an address or latitude and longitude coordinates, allows for searching profiles based on the job's location. We recommend providing jobs in the following structured format if feasible:
{
"title": "...",
"location": "...",
"culture": "...",
"responsibilities": "...",
"requirements": "...",
"benefits": "...",
"other" : {
"contract": "...",
"salary": "...",
...
}
}{
"title": "...",
"description": "..."
}
Job objectIn the example provided above, the
otherfield is intended to hold relevant information that could be attributed to the job as a tag. These tags will serve as valuable search filters.
Jobs naming conventionEach job object should be named with its corresponding reference or id.
3. Application Status
Lets first introduce 2 terms of possible recruiter reviews :
- Trackings : This review represents the application status and links a profile with a job. The status itself is referred to as the action.
- Ratings : This review entails a 5-star score provided by the candidate for a given job.
In this use case, we delve into the utilization of trackings with the following actions: Searched, Visualized, and Applied.
Data qualityIt's imperative to underscore that the quality of the model heavily relies on the quality of the data :
On one hand, the provided data should contain a significant volume of positive signals, such as candidates who have applied or similar data points. The quality of the resulting model directly depends on this quantity as it is usually skewing the distribution of the dataset.
On the other hand, a poorly understood application process results in an inaccurate model, wide attention should be given to :
- Process steps: listing and carefully describing all the different steps of the application process
- Steps links: providing all the possible transitions between each step
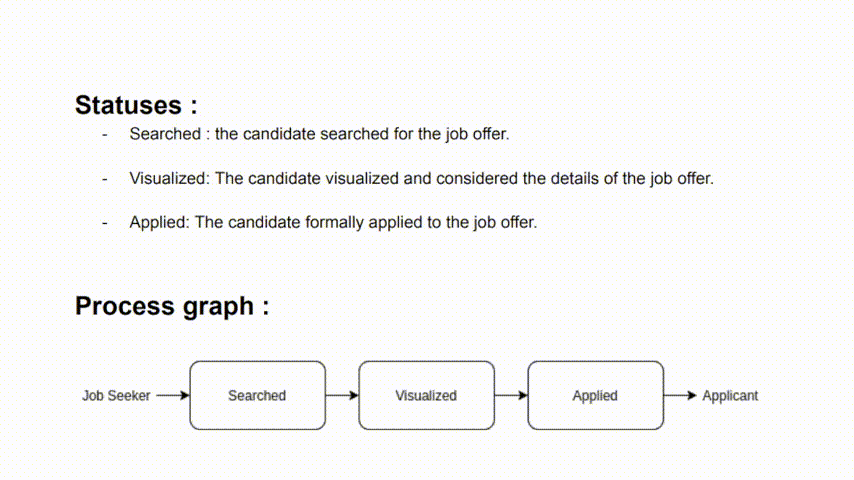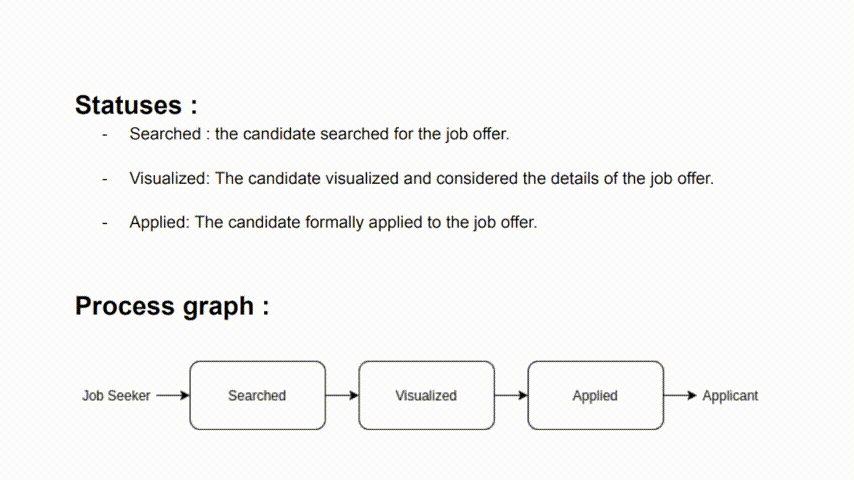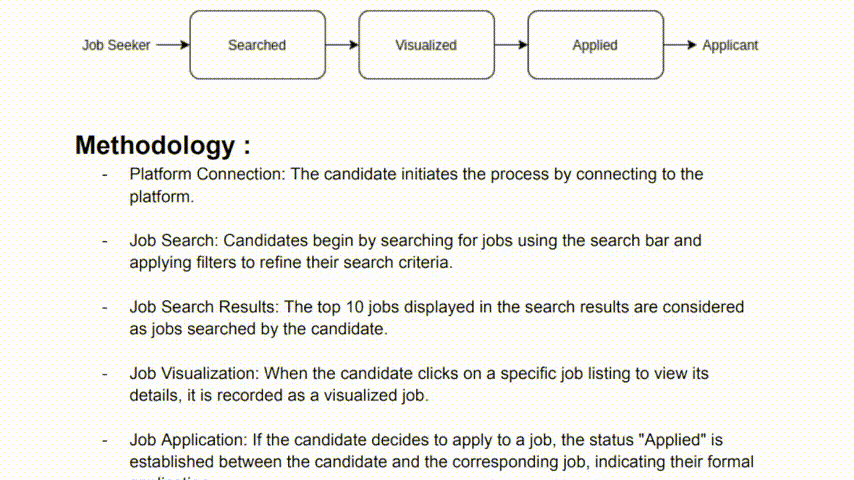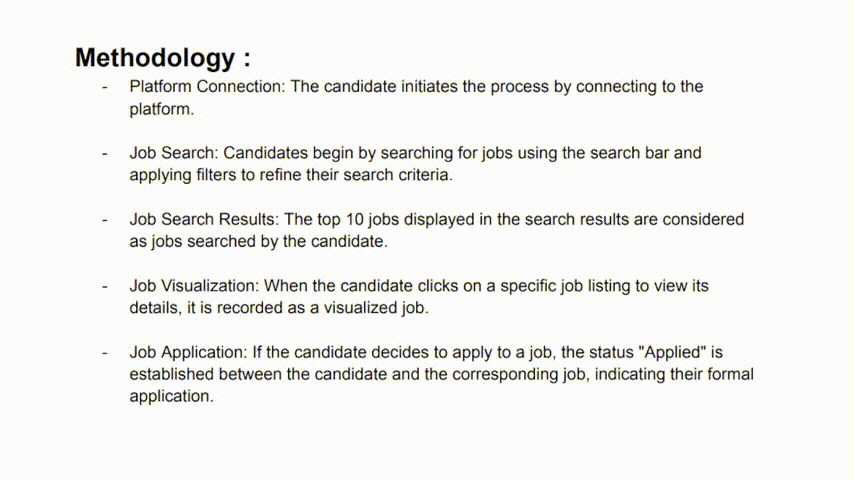
Summarizing the hiring process through a diagram constitutes a good way to depict the links between the steps of the process. For our use case, the steps look like this:

TrackingsTrackings represent the application status. It's crucial to elucidate the significance of each status in the
processfile. This understanding serves to color the graph above, with red indicating negatives and green indicating positives.
II. Format of the Training Data
Your training data should be composed of 4 files :
- resumes.zip: This zip folder contains resumes in various supported extensions such as pdf, docx, images, and more. Optionally, it may include metadata stored in JSON format about each resume, such as the resume category if categorized.
- jobs.zip: This zip folder includes job objects stored as JSON files.
- statuses.json: This JSON file provides the connections between the resumes and the job offers, which could be trackings or ratings. Please refer to the examples below for a better understanding of the format.
- process.pdf: This document outlines the various stages of the application process and how they are linked together. It's essential for understanding the statuses when using trackings during training, as it's the primary method for interpretation. In the case of ratings, this document can detail the process and the individuals responsible for assigning scores. It's typically saved in a PDF or similar file format.
<dataset_directory>/
├── resumes/
| ├── resume_id_00.pdf
| ├── resume_id_00.json
| ├── resume_id_01.png
| ├── resume_id_01.json
| ├── ...
| └── <resume_id>.<resume_extension>
├── jobs/
| ├── job_id_00.json
| ├── job_id_01.json
| ├── ...
| └── <job_id>.json
├── statuses.json
└── process.pdf[
{"job_id": "00", "resume_id": "00", "step": "screening"},
{"job_id": "00", "resume_id": "01", "step": "screening"},
{"job_id": "01", "resume_id": "02", "step": "screening"},
{"job_id": "01", "resume_id": "03", "step": "interview"},
{"job_id": "03", "resume_id": "04", "step": "hired"},
{"job_id": "03", "resume_id": "05", "step": "rejected_after_screening"},
{"job_id": "03", "resume_id": "06", "step": "rejected_after_interview"}
][
{"job_id": "00", "resume_id": "00", "score": 0.2},
{"job_id": "00", "resume_id": "01", "score": 0.4},
{"job_id": "01", "resume_id": "02", "score": 0.2},
{"job_id": "01", "resume_id": "03", "score": 0.4},
{"job_id": "03", "resume_id": "04", "score": 0.8},
{"job_id": "03", "resume_id": "05", "score": 0.2},
{"job_id": "03", "resume_id": "06", "score": 0.6}
]The process.pdf file should contain the following :
- List of all the possible statuses/scores
- Description of each status (for trackings only)
- Graph representing status transitions (for trackings only)
- Method :
- How the statuses/scores are attributed
- Who attributes the statuses/scores (recruiters, managers ...)
Example of the process.pdf file here :
PrerequisitesIn addition, in the scope of retraining a scoring algorithm, we recommend a minimum of:
- 20k unique candidates
- ~500 unique jobs
- 1k positive applications (Applied or similar) is highly recommended.
You are all setWe recommend encrypting the data by zipping it with a password before sending it via WeTransfer to [email protected], replacing 'company_name' with your actual company name. If this method isn't feasible due to large file sizes or security concerns, please utilize Google Drive or another suitable solution.
Once the data has been sent, please send the encryption password to [email protected], again replacing 'company_name' with your company name.
SecurityWe prioritize security and do not entrust any third party. Therefore, please ensure that the zip file is encrypted with a robust password. Once the data is sent, kindly forward the password separately to [email protected], replacing 'company_name' with your company name.
3. Self-Submission :
For users who prefer maximum freedom, we offer the following notebook for uploading profiles, jobs, and trackings to the HrFlow.ai platform. Additionally, you can find other useful code resources here :
- HrFlow Cookbook : Notebook Examples for the Community 😉
4. No-Code : Simplifying Self-Submission Processes :
At HrFlow.ai, we prioritize simplicity and no-code solutions for our customers. That's why we offer no-code approaches for self-submitting profiles, jobs, trackings, or ratings.
1. Candidate profiles :
Prepare parsed profiles in an excel format :
| Template | Example (small version) | Example (medium version) | |
|---|---|---|---|
| Link | Excel Template | Excel Example | Excel Example |
2. Job offers :
Prepare the jobs in an excel format :
| Template | Example (small version) | Example (medium version) | |
|---|---|---|---|
| Link | Excel Template | Excel Example | Excel Example |
3. Statuses :
Fork your algorithm from an existing :
Prepare the trackings in an excel format :
| Template | Example (small version) | Example (medium version) | |
|---|---|---|---|
| Link | Excel Template | Excel Example | Excel Example |
Prepare the ratings in an excel format :
| Template | Example (small version) | Example (medium version) | |
|---|---|---|---|
| Link | Excel Template | Excel Example | Excel Example |
Updated about 2 months ago