Large Scale Scoring Data
Everything you need to know about creating Scoring Data for large scale training
In this guide, we will focus on submitting large-scale datasets to the HrFlow.ai team. For context, refer to the relevant use case based on your viewpoint:
- Recruiter viewpoint: finding the best profiles for a job offer
- Candidate viewpoint: finding interesting jobs for a candidate
Table of Contents
- Profiles Format
- Parquet DataFrames
- HDF5 Files
- Jobs Format
- Parquet DataFrames
- HDF5 Files
- Trackings Format
- Agents Format
- Submit Data
The dataset format used by HrFlow.ai separates actual data from indexation tables.
-
Metadata Storage:
profiles.parquetandjobs.parquetstore metadata for profiles and jobs.profiles_tags.parquetandjobs_tags.parquetstore profile and job tags.
-
Object Storage (HDF5 format):
jobs_objects.h5contains job JSON objects in an array-like format.profiles_objects/0000000-0100000.h5stores profile JSON objects for the range0000000-0100000in an array-like format.
-
Relations & Training:
trackings.parquetdescribes profile-job interactions (e.g., profileiapplied to jobj).agents.parquetdefines the training tree for algorithm training.
Here is an example of the resulting folder architecture :
.
├── agents.parquet
├── jobs_objects.h5
├── jobs.parquet
├── jobs_tags.parquet
├── profiles_objects
│ ├── 0000000-0099999.h5
│ ├── 0100000-0199999.h5
│ ├── 0200000-0299999.h5
│ ├── 0300000-0399999.h5
│ └── 0400000-0499999.h5
├── profiles.parquet
├── profiles_tags.parquet
└── trackings.parquet1. Profiles Format
Profiles are typically the largest and heaviest data in the set. Therefore, we adopted a partitioned storage approach. The partition name 0000000-0100000 indicates it contains JSON objects for elements with IDs from 0 to 100,000 (both included). This requires building a new index where the first profile ID starts at 0, 1, 2, and so on, up to the total number of profiles.
In addition to this storage, two Parquet dataframes are created to ensure easy and efficient access to profiles.
i. Parquet DataFrames :
Two parquet dataframes are used for profiles, profiles.parquet and profiles_tags.parquet.
RequirementsIn addition to
pandasyou will need to install either thefastparquetorpyarrowlibrary
Indexation dataframe (profiles.parquet)
profiles.parquet)The indexation dataframe enables fast and efficient profile searches and links profiles to jobs through trackings. The id column serves as the table's key and must be unique and incremental, starting from 0 (0, 1, 2, ...). The reference is equally important, allowing profiles to be traced back to the original client database if needed.
The rnd and split values separate training and testing profiles. A deterministic approach is recommended, such as generating a uniform random number between 0 and 1 using the profile's hash.
This dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
profiles_columns = [
"id", # Id on this dataset, starts from 0 to len(profiles) - 1
"sql_id", # Optional : Id on the original database
"item_key", # Optional : Key inside the profile JSON object
"provider_key", # Optional : Key of the source containing the profile, else : None
"reference", # Reference of the profile, might be the same as the sql_id
"partition", # Partition where the profile is stored (see the HDF5 part)
"created_at", # Date of creation of the profile
"location_lat", # Optional : Latitude of the profile
"location_lng", # Optional : Longitude of the profile
"experiences_duration", # Optional : Duration of the experiences, included in HrFlow.ai profile objects
"educations_duration", # Optional : Duration of the educations, included in HrFlow.ai profile objects
"gender", # Gender of the profile
"synthetic_model", # Optional : None or model key used to create synthetic sample (ex : hugging face model_key)
"translation_model", # Optional : None or model key used to translate the sample (ex : hugging face model_key)
"tagging_rome_jobtitle", # Optional : Rome job title, else : None
"tagging_rome_category", # Optional : Rome category, else : None
"tagging_rome_subfamily", # Optional : Rome subfamily, else : None
"tagging_rome_family", # Optional : Rome family, else : None
"text", # Optional : Text of the profile (raw text of the parsed profile)
"text_language", # Optional : Language of the text
"split", # Optional : train, test (based on rnd, ex : rnd < 0.8 is train)
"rnd", # Optional : random number (between 0 and 1) used to split the dataset
]Tags dataframe (profile_tags.parquet)
profile_tags.parquet)Tags are values associated with a profile. They can describe the candidate, such as experience level or certifications, or their preferences, like remote work or salary expectations. Tags are flexible—a single candidate can have multiple tags.
Each tag consists of a name and a value. The name represents the tagging referential (e.g., experience_level, remote_work), while the value indicates its state (e.g., senior or mid_level for experience_level).
This dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
tags_columns = [
"profile_id", # Id of the profile, foreign key from the profiles.parquet
"name", # Name of the tag referential, ex : education_level, industry, can_work_in_EU, ...
"value", # Value of the tag, ex : Master, IT, True, ...
]ii. HDF5 Files :
This step requires HrFlow.ai profile parsing. There are two cases:
Profiles Not Parsed by HrFlow.ai :
No need to provide HDF5 files. Instead, submit the raw CVs in the submission folder.
It is mandatory to name the Raw CVs with either the profile id or the reference in the parquet tables
Profiles Parsed by HrFlow.ai :
If profiles are parsed by HrFlow.ai, there is no need to verify the profile JSON formats. They can be downloaded directly from their source or by providing the item_key (equal to key in the profile JSON object).
Below is a Python code snippet to create the HDF5 files :
import json
import os
import h5py
# Partition Parameters
p_size = 100_000 # Partitions chunk size
p_digits = 7 # Number of digits, 7 means a max number of 9_999_999 elements
# Profiles
profiles = [ # The index = id in the porfiles.parquet
json.dumps({"reference": 2200001, "key": "b3368"}, ...),
json.dumps({"reference": 2200002, "key": "1467b"}, ...),
json.dumps({"reference": 2230003, "key": "12349"}, ...),
...
]
# Build Partitions
os.makedirs(os.path.join(path_to_data, "profiles_objects"), exist_ok=True)
for start_id in range(0, len(profiles), p_size):
partition_name = f"{start_id:0{p_digits}d}-{start_id + p_size - 1:0{p_digits}d}"
partition_path = os.path.join(path_to_data, f"profiles_objects/{partition_name}.h5")
with h5py.File(partition_path, "w") as h5py_file:
h5py_file.create_dataset("objects", data=profiles[start_id:start_id + p_size])and here is a Python code snippet to check the loading of a single object :
import json
import os
import h5py
# Profile Id
profile_id = 223_000 # Same as the id in the profiles.parquet
partition = "0200000-0299999" # Same as the partition in the profiles.parquet
# Local partition Id
partition_start_id = int(partition.split("-")[0])
local_profile_id = profile_id - partition_start_id # Arrays always start at 0, first element is 0
# Load the profile
partition_path = os.path.join(path_to_data, f"profiles_objects/{partition}.h5")
with h5py.File(partition_path, "r") as f:
profile = json.loads(f["objects"][local_profile_id])2. Jobs Format
Jobs are typically lighter than profiles and are stored in a single jobs_objects.h5 file containing all job JSON objects. This eliminates the need for partitioning.
In addition to this storage, two Parquet dataframes are created to ensure easy and efficient access to jobs.
i. Parquet DataFrames :
Two parquet dataframes are used for jobs, jobs.parquet and profile_tags.parquet.
RequirementsIn addition to
pandasyou will need to install either thefastparquetorpyarrowlibrary
Indexation dataframe (jobs.parquet)
jobs.parquet)The indexation dataframe enables fast and efficient jobs searches and links jobs to profiles through trackings. The id column serves as the table's key and must be unique and incremental, starting from 0 (0, 1, 2, ...). The reference is equally important, allowing jobs to be traced back to the original client database if needed.
The rnd and split values separate training and testing jobs. A deterministic approach is recommended, such as generating a uniform random number between 0 and 1 using the job's hash.
This dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
job_columns = [
"id", # Id on this dataset, starts from 0 to len(jobs) - 1
"sql_id", # Optional : Id on the original database
"item_key", # Optional : Key inside the job JSON object
"provider_key", # Optional : Key of the source containing the job, else : None
"reference", # Reference of the job, might be the same as the sql_id
"created_at", # Date of creation of the job
"location_lat", # Optional : Latitude of the job
"location_lng", # Optional : Longitude of the job
"synthetic_model", # Optional : None or model key used to create synthetic sample (ex : hugging face model_key)
"translation_model", # Optional : None or model key used to translate the sample (ex : hugging face model_key)
"tagging_rome_jobtitle", # Optional : Rome job title, else : None
"tagging_rome_category", # Optional : Rome category, else : None
"tagging_rome_subfamily", # Optional : Rome subfamily, else : None
"tagging_rome_family", # Optional : Rome family, else : None
"text", # Optional : Text of the job (raw text of the parsed job)
"text_language", # Optional : Language of the text
"split", # Optional : train, test (based on rnd, ex : rnd < 0.8 is train)
"rnd", # Optional : random number (between 0 and 1) used to split the dataset
]Tags dataframe (job_tags.parquet)
job_tags.parquet)Tags are values associated with a job. They can describe the job itself, such as industry or contract type, or specific requirements like remote availability. Tags are flexible—a single job can have multiple tags.
Each tag consists of a name and a value. The name represents the tagging referential (e.g., industry, contract_type), while the value indicates its state (e.g., tech or finance for industry).
This dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
tags_columns = [
"job_id", # Id of the job, foreign key from the jobs.parquet
"name", # Name of the tag referential, ex : industry, contract_type, ...
"value", # Value of the tag, ex : IT, Temporary, ...
]ii. HDF5 File :
Jobs should follow the HrFlow.ai's Job Object structure. More information about in this link.
In addition to the documentation, here below is an example of an HrFlow.ai Job Object :
{
"name": "Regulatory Quality Assurance Manager M/F",
"key": "12343bc6c1b9f47e54567898765432aabcde3293",
"reference": "2983AAU930",
"url": null,
"summary": "Experienced Regulatory Quality Assurance Manager M/F with a demonstrated history of ...",
"created_at": "2021-09-07T14:22:27.000+0000",
"sections": [
{
"name": "job-description",
"title": "Job description",
"description": "..."
},
{
...
}
],
"culture": "XX Company is a global leader in the field of ...",
"responsibilities": "You will be responsible for ...",
"requirements": "You have a degree in ...",
"benefits": "We offer a competitive salary ...",
"location": {
"text": "Paris, France",
"lat": 48.8566,
"lng": 2.3522
},
"skills": [],
"languages": [],
"tasks": [],
"certifications": [],
"courses": [],
"tags": [
{
"name": "experience",
"value": "5-10 years"
},
{
"name": "trial-period",
"value": "3 months"
},
{
"name": "country",
"value": "France"
}
]
}We highly recommend prioritizing the fields culture, responsibilities, requirements, and benefits, but they can be left as null. If any job information cannot fit into these fields, the sections field can be used instead. It is flexible and can contain any kind of sections, though it is deprecated.
Below is a Python code snippet to create the HDF5 file from the job JSON objects :
import json
import os
import h5py
# Jobs
jobs = [ # The index = id in the jobs.parquet
json.dumps({"reference": 2200001, "key": "b3368cec590bfc7e32d73902ca785a4f20a5197b", ...}),
json.dumps({"reference": 2200002, "key": "14678cec590bfc7e32d73902ca785a48287ca97b", ...}),
json.dumps({"reference": 2230003, "key": "12349ec590bfc7e32d73902ca78876463ba6377b", ...}),
...
]
# save jobs in hdf5
hdf5_path = os.path.join(path_to_data, f"job_objects.h5")
with h5py.File(hdf5_path, "w") as h5py_file:
h5py_file.create_dataset("objects", data=jobs)And here is a python code snippet to check the loading of a single object :
import json
import os
import h5py
# Job Id
job_id = 22_000 # Same as the id in the jobs.parquet
# Load the job
hdf5_path = os.path.join(path_to_data, f"job_objects.h5")
with h5py.File(hdf5_path, "r") as f:
job = json.loads(f["objects"][job_id])3. Trackings Format
Trackings represent interactions between jobs and profiles. A tracking consists of an action and metadata, such as the role or author ID. We distinguish between two cases:
- Candidate viewpoint: The tracking
actionreflects the candidate's interaction with the job offer (e.g.,view,apply,accepted). The trackingroleiscandidate, and theauthor_idis theprofile_idor candidate's email. - Recruiter viewpoint: The tracking
actionreflects the recruiter's actions on the candidate's application (e.g.,internet_application,first_interview,technical_interview). The trackingroleisrecruiter, and theauthor_idis the recruiter's ID or email.
The duration of the tracking depends on the action type and is not always defined. Some actions, such as a candidate viewing a job offer or a technical interview, have durations. For example, a candidate viewing a job offer for 10 seconds differs from viewing it for 120 seconds.
The Trackings.parquet dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
tracking_columns = [
"team_id", # Optional : Team id if know, else : None
"author_id", # Optional : identifier (id or email) of the author of the action
"profile_id", # Id of the profile, foreign key from the profiles.parquet
"job_id", # Id of the job, foreign key from the jobs.parquet
"action", # Interaction happening between the profile and the job, ex : view, apply, recruited, ...
"duration", # Optional : Duration of the action in seconds, ex: the action view lasted 10 seconds
"role", # Role of the author of the action, could be one of : recruiter, candidate, employee.
"comment", # Additional comment on the action, ex : reason of the rejection
"timestamp", # timestamp of the creation in seconds, format : 1641004216
"date_edition", # timestamp of the edition in seconds, format : 1641004216
"rnd", # Optional : random number (between 0 and 1) used to split the dataset
]4. Agents Format
To understand the agentic approach, let's first consider the following agent configuration:
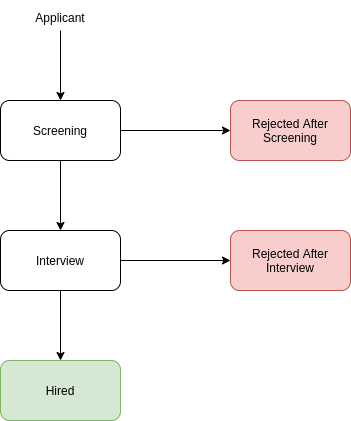
Each block represents a recruiter action. The block's color indicates whether the action is negative (red), positive (green), or neutral (white). This configuration defines the agent setup, which determines the scoring algorithm.
This is the role of the agents.parquet file. It is a dataframe containing at least one row, where each row represents a unique agent configuration. The column training_labels_tracking summarizes this configuration. For the example above, this variable is set as follows:
[
{
"id": 0,
"label": "Screening",
"value": 0,
"principal_input": true, // Starting node is the principal input
"leaf": {
"label": "Rejected After Screening",
"value": -1
}
},
{
"id": 1,
"label": "Interview",
"value": 0,
"principal_input": false,
"leaf": {
"label": "Rejected After Interview",
"value": -1
}
},
{
"id": 2,
"label": "Hired",
"value": 1,
"principal_input": false,
"leaf": null
},
]The agents.parquet dataframe should be a simple Pandas dataframe saved with the to_parquet method. It must include the following columns:
agent_columns = [
"sql_id", # Optional : Id on the original database, else: None.
"agent_key", # Optional : Key identifying the agent.
"training_labels_tracking", # training labels trackings as described above, list of nodes.
"labeler_type", # Role of the action author, could be : recruiter, candidate or employee.
]5. Submit Data
As explained in Part 1.ii, there are two possible cases: whether the CVs are parsed by HrFlow.ai or not. Depending on the situation, the resulting data folder structure differs slightly:
- Profiles Not Parsed by HrFlow.ai :
The resulting folder will have a similar architecture as the following
.
├── agents.parquet
├── jobs_objects.h5
├── jobs.parquet
├── jobs_tags.parquet
├── resumes # CVs are named with the id or the reference
│ ├── 0.pdf
│ ├── 1.png
│ ├── 2.pdf
│ . .....
│ └── n.pdf
├── profiles.parquet
├── profiles_tags.parquet
└── trackings.parquet- Profiles Parsed by HrFlow.ai :
The resulting folder will have a similar architecture as the following
.
├── agents.parquet
├── jobs_objects.h5
├── jobs.parquet
├── jobs_tags.parquet
├── profiles_objects
│ ├── 0000000-0099999.h5
│ ├── 0100000-0199999.h5
│ ├── 0200000-0299999.h5
│ ├── 0300000-0399999.h5
│ └── 0400000-0499999.h5
├── profiles.parquet
├── profiles_tags.parquet
└── trackings.parquet
SecurityWe prioritize security and do not entrust any third party. Therefore, please ensure that the zip file is encrypted with a robust password.
After building the submission folder, the final step is to zip and send it to the HrFlow.ai team.
- The zip folder must be encrypted with a password.
- If needed, the zip archive can be split into multiple smaller chunks.
- We recommend using Google Drive, WeTransfer or similar storage services to store the zip folder.
- Send an email to support+{company_name}@hrflow.ai (replace company_name) containing:
- The link to the data.
- The encryption password.
Updated about 1 year ago