📊 Evaluate a Source of Profiles
Learn how to evaluate the quality of HrFlow.ai's parsing models on your resumes.
This guide offers a comprehensive approach to generating detailed reports and interpreting data from your HR processes. By assessing the completeness and accuracy of your profiles, you can ensure higher quality candidate data, leading to more effective recruitment and talent management.
A. Why Evaluate Parsing Quality?
Understanding the quality of parsing models to accurately detect and fill various fields in a profile is crucial for several reasons:
- Assess Model Performance: Determine which HrFlow.ai parsing model (Quicksilver, Hawk, Mozart) best fits your specific use case.
- Benchmarking: Compare HrFlow.ai's models against competitors to make informed decisions.
B. Step by steps
![]()
B.1. Initialize the HrFlow Client
Prerequisites
- ✨ Create a Workspace
- 🔑 Get your API Key
- HrFlow.ai Python SDK version 4.0.0 or above: Install it via pip with
pip install -U hrflow>=4.0.0or conda withconda install hrflow>=4.0.0 -c conda-forge.
First, initialize the HrFlow client with your API credentials.
from hrflow import Hrflow
from hrflow.utils import generate_parsing_evaluation_report
client = Hrflow(api_secret="your_api_secret", api_user="your_api_user")B.2. Ensure Your Data is Ready
Before generating the parsing evaluation report, you need to ensure that your data is ready. This involves parsing resumes in a source.
The function used for this purpose is add_folder, which parses a folder of profile resumes to a specified source key.
Attention, if you use asynchronous parsingif you use asynchronous parsing, the CVs may take some time to be parsed. Therefore, make sure to wait until all the CVs are parsed and present in the source before moving on to the next step.
Make sure you have created a source and parsed profiles in this source. For more details on creating a source, refer to the Connectors Source Documentation.
import os
STORAGE_DIRECTORY_PATH = "./resumes" # Path where your resumes are stored
FAILURES_DIRECTORY_PATH = "./failures" # Path to store failed parses
os.makedirs(STORAGE_DIRECTORY_PATH, exist_ok=True)
os.makedirs(FAILURES_DIRECTORY_PATH, exist_ok=True)
results = client.profile.parsing.add_folder(
source_key=SOURCE_KEY,
dir_path=STORAGE_DIRECTORY_PATH,
is_recursive=True,
move_failure_to=FAILURES_DIRECTORY_PATH,
show_progress=True,
max_requests_per_minute=30,
min_sleep_per_request=1,
)Field Explanations:
| Parameter | Type | Example | Description |
|---|---|---|---|
source_key | str | "YOUR_SOURCE_KEY" | The key identifying the source where your profiles (CVs) will be stored. This key is unique to the source and is required to specify the destination for the parsed profiles. |
dir_path | str | "./resumes" | The directory path where the resumes to be parsed are stored. This is the path to the folder containing the profile resumes. |
is_recursive | bool | True | Indicates whether to parse files in subfolders as well. If set to True, the function will parse files in the specified directory and all its subdirectories. |
move_failure_to | str or None | "./failures" | The directory path to move the failed files. If set to None, the failed files will not be moved. |
show_progress | bool | True | Indicate whether a progress bar should be displayed during the parsing process. This can be useful for monitoring the progress, especially when processing a large number of resumes. |
max_requests_per_minute | int | 30 | The maximum number of requests that can be made per minute. This is used to rate limit the parsing requests to avoid overloading the server. |
min_sleep_per_request | float | 1 | The minimum time to wait between requests, in seconds. This helps to space out the requests and comply with rate limiting. |
B.3. Generate the Parsing Evaluation Report
Use the generate_parsing_evaluation_report function to create the evaluation report.
generate_parsing_evaluation_report(
client,
source_key="YOUR_SOURCE_KEY",
report_path="parsing-evaluation.xlsx",
show_progress=True,
)Field Explanations:
| Parameter | Type | Example | Description |
|---|---|---|---|
client | Hrflow | client = Hrflow(api_secret="your_api_secret", api_user="your_api_user") | The HrFlow client object initialized with your API credentials. This client is used to interact with the HrFlow.ai API and is necessary for authenticating and authorizing the API requests. |
source_key | str | "YOUR_SOURCE_KEY" | The key identifying the source where your profiles (CVs) are stored. This key is unique to the source and is required to specify which set of profiles you want to evaluate. |
report_path | str | "parsing-evaluation.xlsx" or "/path/to/directory/parsing-evaluation" | The file path where the evaluation report will be saved. This can either be an existing directory, in which case the report will be saved as parsing_evaluation.xlsx within that directory, or a complete file path. If the provided path does not end in .xlsx, the function will automatically append the .xlsx extension to the path. |
show_progress | bool | True to show the progress bar, False to disable it. | A flag to indicate whether a progress bar should be displayed during the generation of the report. This can be useful for monitoring the progress, especially when processing a large number of profiles. |
B.4 Interpreting the Results
The generated report is an Excel file named parsing-evaluation.xlsx that provides a detailed assessment of the quality of parsing models to detect and fill various fields in profiles stored in the specified HrFlow source.
The report consists of two sheets:
-
Definition: This sheet explains each field and how to interpret the results.
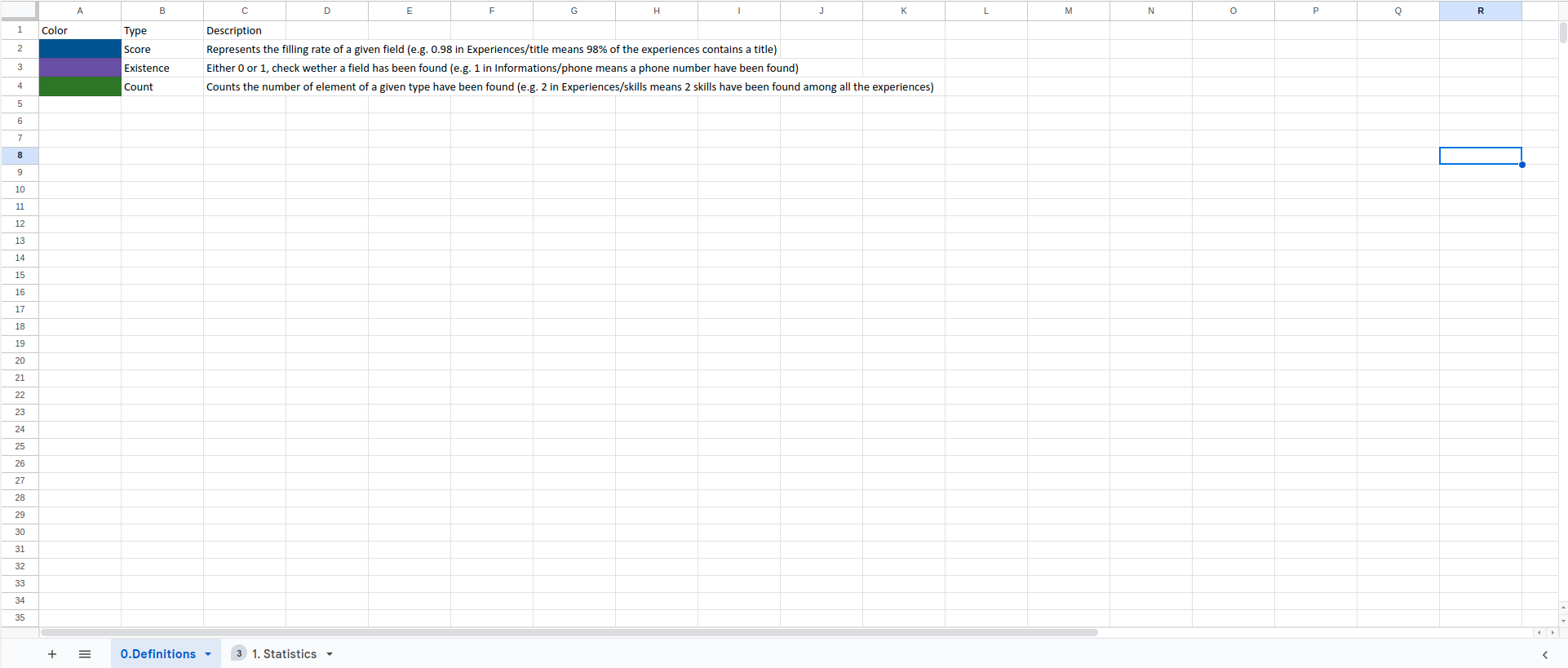
- Score : Represents the filling rate of a given field (e.g. 0.98 in Experiences/title means 98% of the experiences contains a title)
- Existence : Either 0 or 1, check wether a field has been found (e.g. 1 in Informations/phone means a phone number have been found)
- Count : Counts the number of element of a given type have been found (e.g. 2 in Experiences/skills means 2 skills have been found among all the experiences)
-
Statistics: This sheet presents a comprehensive set of results, offering insights into parsing quality across various sections such as personal info, experience, education, and other skills.
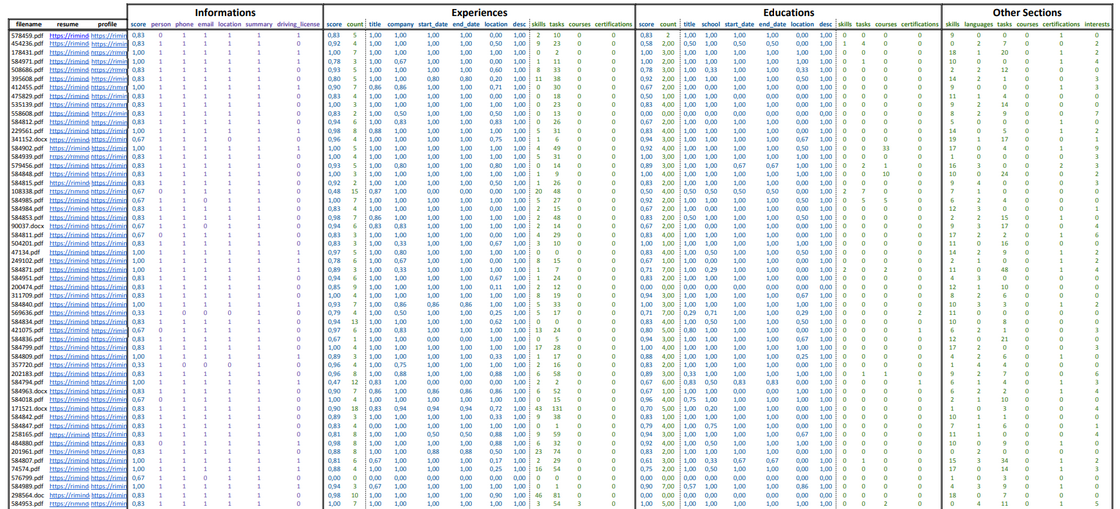
- General Information:
- filename: The name of the file containing the profile.
- resume: A link to the resume.
- profile: A link to the parsed profile JSON in HrFlow.ai.
- Information:
- score: Overall score for personal information. It's an average on all personal info fields.
- person, phone, email, location, summary, driving_license: Scores indicating the presence and completeness of each type of information.
- Experiences:
- score: Overall score for the experience section. It's an average on all experience score fields.
- count: The number of experiences detected.
- title, company, start_date, end_date, location, desc: Scores for the presence and completeness of each field within experiences.
- skills, tasks, courses, certifications: Counts of additional elements found within experiences.
- Educations:
- score: Overall score for the education section. It's an average on all experience score fields.
- count: The number of education entries detected.
- title, school, start_date, end_date, location, desc: Scores for the presence and completeness of each field within education.
- skills, tasks, courses, certifications: Counts of additional elements found within education.
- Other Sections:
- skills: Total number of skills detected across the entire profile.
- languages: Total number of languages detected.
- tasks: Total number of tasks detected.
- courses: Total number of courses detected.
- certifications: Total number of certifications detected.
- interests: Total number of interests detected.
- General Information:
Key Points to Note
- Scores Reflect Completeness: A low score may indicate missing information in the resumes rather than poor parsing performance.
- Context Matters: For anonymized resumes, expect lower scores in personal information fields due to the absence of such data.
D. Additional Resources
- Feature Announcement
- HrFlow.ai Python SDK on PyPI
- HrFlow Cookbook : Repository containing helpful notebooks by the HrFlow.ai team
- Parsing Evaluator Notebook in Colab

Updated about 1 year ago